RADOS
Created Sunday 05 April 2020
ABSTRAKT
Mursten og objektbaserede opbevaringsarkitekturer er dukket op som et middel til at forbedre skalerbarheden i lagringsklynger. Imidlertid behandler eksisterende systemer fortsat lagringsnoder som passive enheder på trods af deres evne til at udstille markante intelligens og autonomi. Vi præsenterer design og implementering af RADOS, en pålidelig objektopbevaringstjeneste der kan skaleres til mange tusinder af enheder ved at udnytte den intelligens, der er til stede i individuelle lagringsnoder. RADOS bevarer konsistent datatilgang og stærk sikkerhedssemantik, samtidig med at knudepunkter kan fungere semi-autonomt for selvstyring af replikering, fejldetektering og gendannelse af fejl ved hjælp af et lille klynkekort. Vores implementering tilbyder fremragende ydelse, pålidelighed og skalerbarhedsamtidig med at klienterne får illusionen om en enkelt logisk objekt butik.
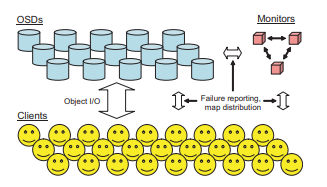
Figur 1: En klynge på mange tusinder af OSD'er holder alle objekter i systemet. En lille, tæt koblet
klynge af monitors administrerer samlet det klynkekort, der specificerer klyngemedlemskab og
distribution af data. Hver klient udsætter en enkel lagergrænseflade til applikationer.
- INTRODUKTION
været en løbende udfordring for systemdesignere. Høj gennemstrømning
og lav latenslagring til filsystemer, databaser og relaterede abstraktioner er kritiske for udførelsen af en bred
række applikationer. Emerging clustered opbevaring arkitekturer konstrueret af opbevaring mursten eller objekt opbevaringsenheder (OSD'er) søger at distribuere lavt niveau blok allokering
beslutninger og sikkerhedshåndhævelse til intelligente lagringsenheder, forenkling af datalayout og eliminering af I / O-flaskehalse ved at lette direkte klientadgang til data [1, 6, 7, 8,
21, 27, 29, 31]. OSD'er konstrueret af råvarekomponenter kombinerer en CPU, netværksgrænseflade og lokal cache
med en underliggende disk eller RAID og erstatte konventionens blokbaserede lagergrænseflade med en baseret på navngivet,
objekter med variabel længde.
Systemer, der anvender denne arkitektur, lykkes imidlertid stort set ikke
udnytte enhedens intelligens. Som i konventionelle lagringssystemer baseret på lokale eller netværksbundne (SAN) diskdrev
eller dem, der omfatter den foreslåede T10 OSD-standard, enheder
reagerer passivt på læse og skrive kommandoer, på trods af deres
potentiale til at indkapsle betydelig intelligens. Som opbevaring
klynger vokser til tusinder af enheder eller mere, konsekvent
styring af dataplacering, fejldetektering og fejlgendannelse lægger en stadig større byrde for klienten,
controller eller metadata-katalognoder, der begrænser skalerbarheden.
Vi har designet og implementeret RADOS, en pålidelig, autonom distribueret objektbutik, der søger at udnytte enhedens intelligens til at distribuere kompleksiteten omkring
konsekvent datatilgang, overflødig opbevaring, fejlregistrering,
og bedring af fiasko i klynger bestående af mange tusinder
af lagerenheder. Bygget som en del af Ceph distribueret fil
system [27] letter RADOS en udviklende, afbalanceret distribution af data og arbejdsbyrde på tværs af en dynamisk og heterogen lagringsklynge, mens applikationer leveres med
illusionen af et enkelt logisk objektlager med veldefineret
sikkerhedssemantik og stærk konsistensgarantier.
I petabyte-skalaen er lagringssystemer nødvendigvis dynamiske: de er bygget gradvis, de vokser og trækker sig sammen
med implementering af nyt lager og nedlæggelse af
gamle enheder, enheder mislykkes og gendannes kontinuerligt,
og store mængder data oprettes og ødelægges. RADOS sikrer et ensartet overblik over datadistributionen og
konsekvent læse- og skriveadgang til dataobjekter gennem
brug af et versioneret klynkekort. Kortet gentages af
alle parter (både lager- og klientnoder) og opdateret af
dovende formerer små trinvise opdateringer.
Ved at tilvejebringe lagringsnoder med fuld viden om
distribution af data i systemerne, enheder kan handle semiautonomisk ved hjælp af peer-to-peer-lignende protokoller til selvstyring
datareplikering, konsekvent og sikkert behandle opdateringer,
deltage i fejldetektering og svar på enhedsfejl-
ures og de deraf følgende ændringer i distributionen af data
ved at gentage eller migrere dataobjekter. Dette letter
byrde på den lille skærmklynge, der administrerer masterkopien af klyngekortet og derigennem resten af
lagringsklynge, der gør det muligt for systemet problemfrit at skalere fra
et par dusin til mange tusinder af enheder.
Vores prototypeimplementering afslører en objektgrænseflade
hvor byteomfang kan læses eller skrives (omtrent som a
fil), da det var vores oprindelige krav til Ceph. Dataobjekter replikeres n måder på tværs af flere OSD'er til beskyttelse
mod knudepunktfejl. Dog skalerbarheden af RADOS
er på ingen måde afhængig af den specifikke objektgrænseflade eller
redundansstrategi; objekter, der gemmer nøgle / værdipar og
paritetsbaseret (RAID) redundans er begge planlagt.
- SKALERBARE KLUSTERHåndtering
en lille gruppe af skærme, der er ansvarlige for styring af OSD
klyngemedlemskab (figur 1). Hver OSD inkluderer en CPU,
noget flygtigt RAM, en netværksgrænseflade og et lokalt tilsluttet diskdrev eller RAID. Skærme er selvstændige processer og kræver en lille mængde lokal opbevaring.
2.1 Cluster Map
Lagringsklyngen styres udelukkende gennem manipulation af klyngekortet af skærmklyngen. Det
kort specificerer hvilke OSD'er der er inkluderet i klyngen og
specificerer kompakt distributionen af alle data i systemet på tværs af disse enheder. Det replikeres ved enhver opbevaring
node samt klienter, der interagerer med RADOS-klyngen.
Da klyngekortet fuldstændigt specificerer datadistributionen, udsætter klienter en simpel grænseflade, der behandler hele lagringsklyngen (potentielt titusinder af noder)
som et enkelt logisk objektlager.
Hver gang ændres klynkekortet på grund af en OSD-status
ændring (f.eks. enhedens fiasko) eller andre data, der påvirker begivenheden
layout, kortepoken forøges. Kortepoker tillader
kommunikere parter til at blive enige om, hvad den aktuelle distribution af data er, og til at bestemme, hvornår deres oplysninger er
epoke: kortrevision
op: OSD 7 → {netværksadresse, ned}
i: OSD 7 → {ind, ud}
m: antal placeringsgrupper (2k - 1)
crush: CRUSH hierarki og placeringsregler
Tabel 1: Klyngekortet specificerer klyngemedlemskab, enhedsstatus og kortlægning af dataobjekter
til enheder. Datadistributionen specificeres først af
kortlægning af objekter til placeringsgrupper (kontrolleret af
m) og derefter kortlægge hver PG på et sæt enheder
(CRUSH).
er (relativt) ude af data. Fordi klynkekort ændres
kan være hyppig, da der i et meget stort system, hvor OSD-fejl og gendannelse er normen, opdateres distribueres
som inkrementelle kort: små beskeder, der beskriver forskellene mellem to på hinanden følgende epoker. I de fleste tilfælde sådan
opdateringer angiver blot, at en eller flere OSD'er er mislykkedes
eller gendannes, selvom de generelt kan omfatte status
ændringer for mange enheder, og flere opdateringer kan være samlet sammen for at beskrive forskellen mellem fjernt kort
epoker.
2.2 Dataplacering
RADOS anvender en datadistributionspolitik, hvor objekter er genstand
er pseudo-tilfældigt tildelt enheder. Når nyt lager
tilføjes, migreres en tilfældig underprøve af eksisterende data
til nye enheder for at gendanne balance. Denne strategi er robust
ved at det opretholder en sandsynligt afbalanceret fordeling
at gennemsnitligt holder alle enheder på samme måde indlæst, så systemet kan fungere godt under potentiel arbejdsbelastning [22]. Vigtigst er dataplacering i to faser
proces, der beregner den rigtige placering af objekter; ingen
der kræves en stor eller besværlig centraliseret allokeringstabel.
Hvert objekt, der er gemt af systemet, kortlægges først til et
placeringsgruppe (PG), en logisk samling af objekter der
replikeres af det samme sæt enheder. Hvert objekts PG
bestemmes af en hash af objektnavnet o, det ønskede
replikationsniveau r, og en bitmaske m, der styrer
samlet antal placeringsgrupper i systemet. Det er,
pgid = (r, hash (o) & m), hvor & er en smule klog OG og
maske m = 2k − 1, begrænser antallet af PG'er med en magt
af to. Når klyngen skaleres, er det periodisk nødvendigt at gøre det
juster det samlede antal placeringsgrupper ved at ændre
m; dette gøres gradvist for at smøre den resulterende migration
af PG'er mellem enheder.
Placeringsgrupper tildeles OSD'er baseret på klyngen
kort, som kortlægger hver PG til en ordnet liste over r OSD'er på
som man skal gemme objektreplikater. Vores implementering bruger
CRUSH, en robust replikadistributionsalgoritme, der beregner en stabil, pseudo-tilfældig kortlægning [28]. (Andre placeringsstrategier er mulige; selv en eksplicit tabel, der kortlægger hver PG til et sæt enheder, er stadig relativt lille
(megabyte) selv for ekstremt store klynger.) Fra en høj
niveau, CRUSH opfører sig på samme måde som en hash-funktion: placeringsgrupper er deterministisk men pseudo-tilfældigt fordelt. I modsætning til en hash-funktion er CRUSH imidlertid stabil:
når en (eller mange) enheder slutter sig til eller forlader klyngen, mest
PG'er forbliver, hvor de er; CRUSH skifter lige nok data
at opretholde en afbalanceret fordeling. I modsætning hertil
fremgangsmåder tvinger typisk til en omskiftning af alle tidligere kortlægninger.
CRUSH bruger også vægte til at kontrollere den relative mængde af
data tildelt til hver enhed baseret på dens kapacitet eller ydelse.
Placeringsgrupper giver et middel til at kontrollere niveauet for
replikering afvisning. Det vil sige i stedet for en OSD-deling
alle dets kopier med et eller flere enheder (spejling) eller
med deling af hvert objekt med forskellige enheder (r) (komplet
declustering), er antallet af replikations-peers relateret til
antallet af PG'er µ det gemmer — typisk i størrelsesordenen 100
PG'er pr. OSD. Da distribution er stokastisk, påvirker µ også variationen i enhedsanvendelser: flere PG'er pr. OSD
resultere i en mere afbalanceret fordeling. Vigtigere,
declustering letter distribueret, parallel mislykket gendannelse
ved at tillade, at hver PG gentages uafhængigt fra
og til forskellige OSD'er. På samme tid kan systemet
begrænse eksponeringen for sammenfaldende enhedsfejl ved at begrænse
antallet af OSD'er, som hver enhed deler fælles med
data.
2.3 Enhedstilstand
Klyngekortet inkluderer en beskrivelse og den aktuelle tilstand
af enheder, som data distribueres over. Dette inkluderer
nuværende netværksadresse for alle OSD'er, der i øjeblikket er online
og kan nås (op), og en indikation af, hvilke enheder der er
i øjeblikket nede. RADOS betragter en yderligere dimension
af OSD-livskraft: i enheder er inkluderet i kortlægningen og
tildelte placeringsgrupper, mens ud-enheder ikke er det.
For hver PG producerer CRUSH en liste over nøjagtigt r OSD'er der
er i kortlægningen. RADOS filtrerer derefter enheder der
er nede for at fremstille listen over aktive OSD'er for PG. Hvis
den aktive liste er i øjeblikket tom, PG-data er midlertidigt
ikke tilgængelig, og afventende I / O er blokeret.
OSD'er er normalt både op og i kortlægningen for aktivt
service I / O, eller begge ned og ud, hvis de er mislykkedes, og producerer en aktiv liste over nøjagtigt r OSD'er. OSD'er kan det også være
nede, men stadig under kortlægningen, hvilket betyder, at de i øjeblikket ikke kan nås, men PG-data er endnu ikke blevet omappet
til en anden OSD (svarende til “nedbrudt tilstand” i RAID
systemer). På samme måde kan de være op og ud, hvilket betyder, at de er
er online men inaktiv. Dette letter en række scenarier,
inklusive tolerance for intermitterende perioder med utilgængelighed
(f.eks. en OSD-genstart eller netværkshik) uden at iværksætte nogen datamigrering, muligheden for at bringe nyudviklet
opbevaring online uden at bruge det øjeblikkeligt (f.eks. for at tillade
det netværk, der skal testes), og muligheden for sikkert at migrere
data fra gamle enheder, før de tages ud af drift.
2.4 Kortformering
Fordi RADOS-klyngen kan omfatte mange tusinder
af enheder eller mere, er det ikke praktisk at blot udsende
kortopdateringer til alle parter. Heldigvis forskelle i kort
epoker er kun signifikante, når de varierer mellem to kommunikerende OSD'er (eller mellem en klient og OSD), som
skal blive enige om deres rette roller med hensyn til den særlige PG I / O-referencer. Denne egenskab tillader RADOS at
distribuer kortopdateringer dovne ved at kombinere dem med eksisterende inter-OSD-meddelelser og effektivt skifte distribution
byrde for OSD'er.
Hver OSD opretholder en historie med tidligere inkrementelle kortopdateringer, mærker alle meddelelser med sin seneste epoke og holder
spor af den seneste tid, der observeres at være til stede ved hver
peer. Hvis en OSD modtager en meddelelse fra en peer med en ældre
kort, det deler de nødvendige trin (er) for at bringe det
peer synkroniseret. Tilsvarende når man kontakter en peer tænkt på
har en ældre epoke, inkrementelle opdateringer er præemptivt
delt. Hjertslagsmeddelelserne udveksles med jævne mellemrum
fejldetektering (se Afsnit 3.3) sikre, at opdateringer spreder sig
hurtigt — i O (log n) tid til en klynge af n OSD'er.
For eksempel, når en OSD først starter, begynder den med at informere en skærm (se Afsnit 4), der er kommet online med en
OSDBoot-meddelelse, der inkluderer dens seneste kortepoke.
Skærmklyngen ændrer OSD's status til op, og
svar med de trinvise opdateringer, der er nødvendige for at bringe
OSD er helt opdateret. Når den nye OSD begynder at kontakte OSD'er, som den deler data med (se Afsnit 3.4.1), the
nøjagtigt sæt enheder, der er påvirket af dets statusændring
lære om de relevante kortopdateringer. Fordi en opstart OSD endnu ikke ved nøjagtigt hvilke epoker dens jævnaldrende
har, den deler en sikker nyere historie (mindst 30 sekunder) af
trinvise opdateringer.
Denne forebyggende kortdelingsstrategi er konservativ: an
OSD deler altid en opdatering, når du kontakter en peer
medmindre det er sikkert, at peeren allerede har set det, hvilket resulterer
i OSD'er, der modtager duplikater af den samme opdatering. Imidlertid,
antallet af duplikater, en OSD modtager, er afgrænset af
antallet af kammerater, det har, hvilket igen bestemmes af
antal PG'er µ det administrerer. I praksis finder vi ud af, at
Det faktiske niveau af opdateringsduplikation er meget lavere end dette
(se afsnit 5.1).
- INTELLIGENT OPBEVARINGSANORDNINGER
Om ZIM.smarken.net
Backlinks: Teknik 1wiki:Teknologier:Hardware:Raspberry PI:distroer:opensuse:Kubic:RPI4-yast-software:ceph:Anvendelse